Follow-up to the first post. Four days of real ticket work later. The shape of it: three Claude sessions running, an IDE I haven’t opened, and a quota I keep walking into.
Where I am
The contracts-and-codegen epic is done. The identity epic has the guest-session and profile-page tickets done, and the upgrade-and-login one in flight — server slice landed, client slice next. The content epic has the first three tickets done; the maps-and-importer one is on a separate worktree right now. Deployment got a main-preview-stack ticket. There’s also a cross-cutting SignalR-hub ticket in flight outside any specific epic. So: roughly nine tickets shipped across four epics that have seen any work at all, with three more in progress.
That’s not a lot of volume in absolute terms. It’s enough that the workflow is no longer theoretical.
Parallel sessions are the upgrade
The biggest behavioural change since post 1: I started with one Claude session at a time, moved to two when that worked, and I’m running three now.
The interaction loop looks like this. When I’m ready to start something, I ask the current session “what’s next.” It looks at the roadmap, looks at the blocked-by graph, and gives me a list of candidates. I pick one for that session to keep working on, and for each of the others I open a fresh session and tell it “this one’s the maps-and-importer ticket, create a worktree and go.” I don’t narrate the dependency graph or the codebase shape; the ticket files do that for me. The blocked-by field is what makes the candidate list trustworthy — Claude isn’t going to suggest something that depends on work that hasn’t shipped yet.
Concretely, here’s the “what’s next” turn from the start of today’s session — trimmed:
> what's next
[... reads the roadmap, runs `git log origin/main..HEAD`, `gh pr list`, `git fetch` to check what's merged ...]
PR #30 (E002-T0002 profile client) merged into main as fa6e61f. The local
feat/e002-t0002-profile-client branch is stale — that's the first cleanup
step before anything new.
Status snapshot:
E002 Identity — T0001, T0002 done. Remaining:
- T0003 — Account upgrade and login (planned)
- T0004 — Email confirmation and password reset (planned)
- T0005 — Guest garbage collection (planned)
Other active work — E011 Deployment is the only other in-progress epic
(PR preview stack done; production target / scaling / CDN / release process
still ahead).
Suggested next move: start E002-T0003. It's the natural follow-up to the
profile work (extends Profile + Accounts surface with credentials + login),
unblocks T0004 (which relies on real accounts existing), and keeps you in
the identity area while the context is hot.
[... offers two options: cleanup + plan T0003, or look at something else ...]
That’s the shape: what shipped, what’s planned, a recommendation with the dependency reasoning attached, and a question back. From here I either say “go” or redirect — in this case I picked T0003, which is the upgrade-and-login session still running.
Right now the three live sessions are upgrade-and-login, the maps importer, and the SignalR hub (a cross-cutting ticket, outside any specific epic). They don’t touch the same files. They don’t need to know about each other.
Git worktrees are the other piece. I didn’t know about them until a few weeks ago — they showed up in Rider’s git UI in a recent update and that’s how I discovered the feature exists. Before that I’d been doing the obvious-but-bad thing of cloning the repo multiple times when I needed to work on more than one branch at once. With three Claude sessions on three branches, worktrees pay off immediately: no extra clones, no stash dance, the trees sit next to each other on disk, one per active branch. (Mildly embarrassing that I needed Rider’s UI to find a feature that’s been in git for a decade. Whatever.)
One more thing that makes parallel sessions tractable: Claude does the git ceremony. I told it to commit small and push often, and it does. The result is a stream of granular commits I can read on GitHub as work progresses, not a giant end-of-ticket dump.
Merging is a design event
Parallel sessions don’t usually fight over code paths — picking unblocked tickets sees to that. But branches still need to be merged, and design decisions in one branch can affect code that’s already landed in another, even with no textual conflict. So how Claude handles a merge matters more than I expected: it’s the difference between sessions I can leave running and sessions where I have to step in every time two branches converge.
Textual conflicts are easy: two branches both appending to the same list, two status flips on the same ticket, that kind of thing. Claude resolves those without my involvement.
The case that stuck with me isn’t textual at all. One session — working on the content endpoints — changed a spec decision: we’d been camelCase in DTOs, the spec flipped to kebab-case for query strings. When I asked another session, working on the profile endpoints, to merge its branch in, the merge itself was clean — the two branches had touched different files, so there was no textual conflict to resolve. But Claude noticed the spec diff coming in from the other branch, updated the requests it had added in its branch to use kebab-case, and then completed the merge.
No failing test prompted this. No hint from me. It read the design change and reconciled its own work to it. That’s not “good at merge conflicts” — that’s reading the merge as a design event and adjusting accordingly.
Token usage isn’t a surprise but it bites anyway
Token cost is the thing everyone in AI tooling is talking about right now, so I came in expecting to feel it. There’s a difference between “I expected it” and “I felt it,” and the second one shows up faster than I thought.
Worth setting expectations on what this project is. The point of this experiment is to see what Claude alone produces, so I’m explicitly not stepping in to write code when something stalls. That’s what turns “quota is annoying” into “quota is a blocker.” If I were happy to drop into the editor and unstick myself, the cost question would look different.
What I didn’t quite anticipate: three sessions, deeper tickets, and heavier sub-agent use compound faster than I expected. A 5-hour quota window now runs out in roughly three hours of real work. Quota stopped being a number I noticed and became a ceiling I run into — one day I stopped after about two and a half hours and waited two more hours for the next reset before I could pick the work back up.
A specific moment from yesterday, separate from the above: I’d hit the quota mid-session and left the terminal open. A few hours later, after the reset, I just typed continue. That one turn — Claude rehydrating the whole transcript and continuing where it left off — consumed about 30% of the fresh 5-hour budget. I don’t yet know whether the right answer is to start fresh sessions instead of resuming, summarise hard before resuming, or accept it and plan around it.
My current hypothesis — hypothesis, not a finding — is that “one Claude session per ticket” is the wrong unit. A ticket can be hours of work; the context at hour three is much bigger than at hour zero, and most of it isn’t relevant to the current turn. So either:
- I split a ticket across multiple shorter sessions, restarting the context at natural seams (server slice done, start a fresh session for the client slice), or
- I cut tickets smaller in the first place, so a ticket fits a single short session by construction.
I don’t know which is right. Smaller tickets feel like the cleaner answer because it makes the unit-of-work stable across both me and Claude, but it also means more roadmap churn, and I can already see how easy it would be to over-fragment. I’m going to try the “split mid-ticket” approach first — it doesn’t require restructuring the roadmap — and revisit if it doesn’t help.
Scope creep: the heraldry editor
One concrete failure mode worth recording. The profile-page ticket said: a preset avatar grid, a small curated set, image upload explicitly out.
What shipped: no preset grid at all, identicons as the only avatar baseline, and a full heraldry editor at /avatar with palette, glyph, decoration count, shape, and glow controls — backed by a 12-hex avatar code that round-trips between URL parameters and a printable string. About 30 commits beyond the original ticket.
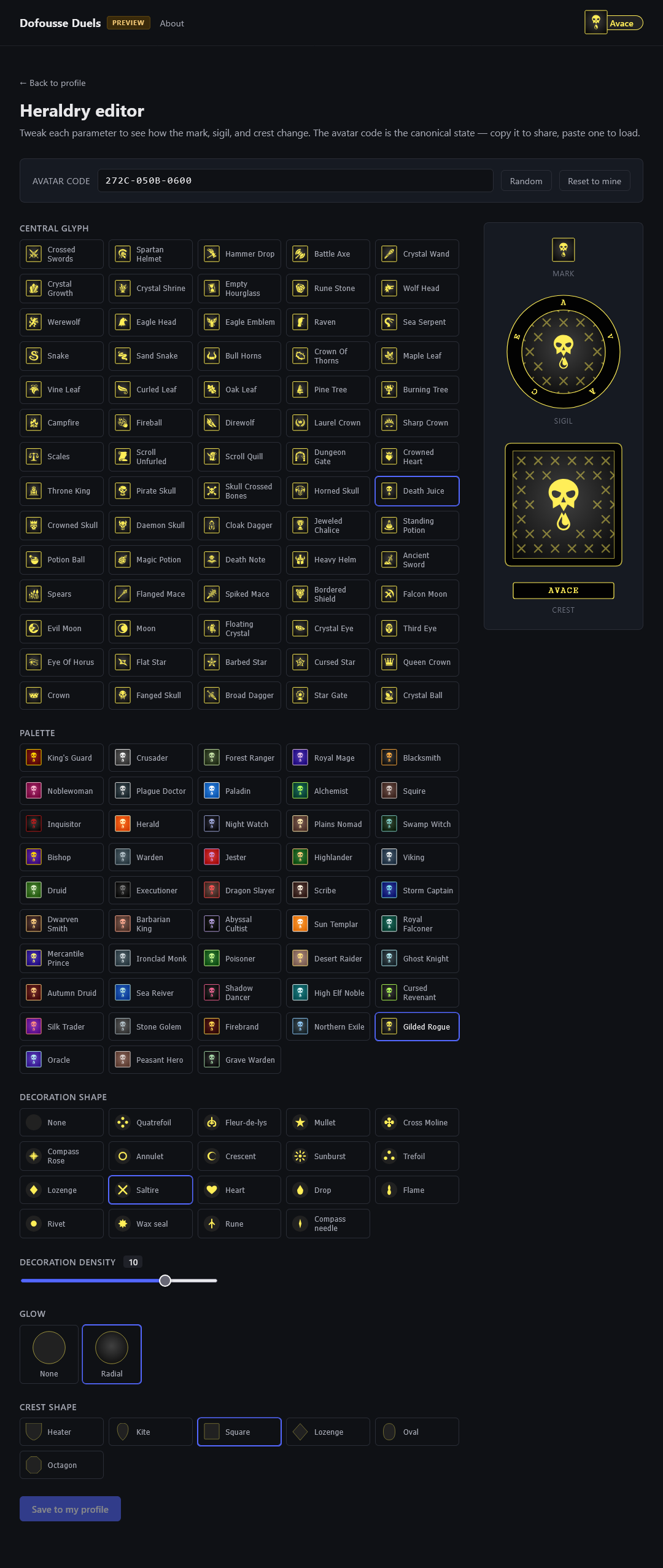
I love the result. The heraldry editor is the most fun part of the app right now. But it was not in scope for that ticket, and it should have been a new ticket as soon as it became clear the idea was bigger than “swap the preset selector for an identicon.” Claude flagged the over-scope at the time. I waved it through because I was enjoying it.
The ticket file ended up with an honest postmortem on it:
[... original scope: preset grid + chat prefs ...]
### Pivot 2 — heraldry editor
The identicon stayed, but a follow-on idea took over: rather than a
fixed identicon shape, let the user *edit* the symbology — palette,
glyph, decoration count, shape, glow — and save the result.
[... details: /avatar sub-page, three preview variants, 12-hex avatar code ...]
### Scope honesty
The heraldry editor (commits from `59c991a` onwards, ~30 commits) was
substantial enough to deserve its own ticket and is largely unrelated
to the profile-page outcome described above. It's bundled here because
it grew incrementally on the same branch rather than being recognised
as a new ticket up front.
Two things from this. First: the system did warn me. The PM-in-the-room metaphor from post 1 wasn’t only for the spec phase — it surfaces during execution too. Second: knowing the system would warn me didn’t stop me from ignoring the warning. That’s discipline, not a workflow problem. The workflow gave me the data; I chose not to act on it. Worth flagging because it’ll happen again.
I stopped opening my IDE on this project
At some point I stopped opening Rider on this repo — not deliberately, I just didn’t need to. The actions I’d traditionally use the IDE for are now either simple terminal commands or things Claude handles. I still launch Rider daily for the day job and other personal projects; I’ve just stopped opening it for this one.
A few things conspired to make that fine:
- Local dev is a terminal command.
aspire runbrings up the server, the database, and the supporting services in one go. I run it when I want to click around the app, and stop it when I want Claude to run tests against the same ports. - CI on every PR, with integration tests Claude wrote. I asked Claude to add integration tests for each new feature, and I read those tests during PR review. The combination of “I read the test” plus “CI runs the test” gives me enough confidence that I don’t feel the need to step through code locally.
- Auto-deploy to a preview subdomain. Each PR auto-deploys to a preview environment on a small VM I own (both the deploy workflow and the CI workflow above are GitHub Actions Claude wrote — I haven’t touched CI YAML on this project). I open the running deployment in a browser, click through the feature on real infrastructure, and only then approve. Reviewing in the actual UI is closer to what I’d have used the IDE’s debugger for anyway.
- Git ceremony lives in the session. The bits of the IDE I’d traditionally use for git aren’t on the path.
The bullets above don’t say anything about a debugger because I haven’t needed one. When something fails — a test, a build, a runtime issue in the preview environment — Claude has fixed it without me. I haven’t measured whether asking Claude to fix something is more or less expensive than fixing it myself; for small bugs the latter is probably cheaper. The premise of this project is to use AI as much as possible, so I’m not optimising that tradeoff yet — but I’m noting it so future-me knows it wasn’t measured.
I’m not claiming this is good in general. It’s the empirical state of how I’m working on this one. (Subjective: it feels lighter than I expected. I’d have predicted I’d miss the IDE more.)
What I’m still figuring out
- Token efficiency. This is the one I most want to figure out. Three sessions is a force multiplier if I can keep each session’s context lean. The 30%-on-resume episode tells me I haven’t found the right session-reuse pattern yet.
- Whether three is my ceiling. I don’t think I have the headspace for four — context-switching between three is already noticeable — but that’s about me, not the workflow.
- Whether “Claude warned, I didn’t listen” generalises. The heraldry case was clearly me. I’d want more data points before concluding the warning signal is reliable in both directions.
Status check in the next post. I’d guess two weeks.